AI Test Lab
Metadata labeling and embeddings strategy for production readiness.
If you can't test it, you shouldn't deploy it. AI Test Lab gives teams a dedicated validation layer to test prompts, models, pipelines, and outputs before they hit production, helping organizations enter the AI game without taking on high expense and unnecessary risk.
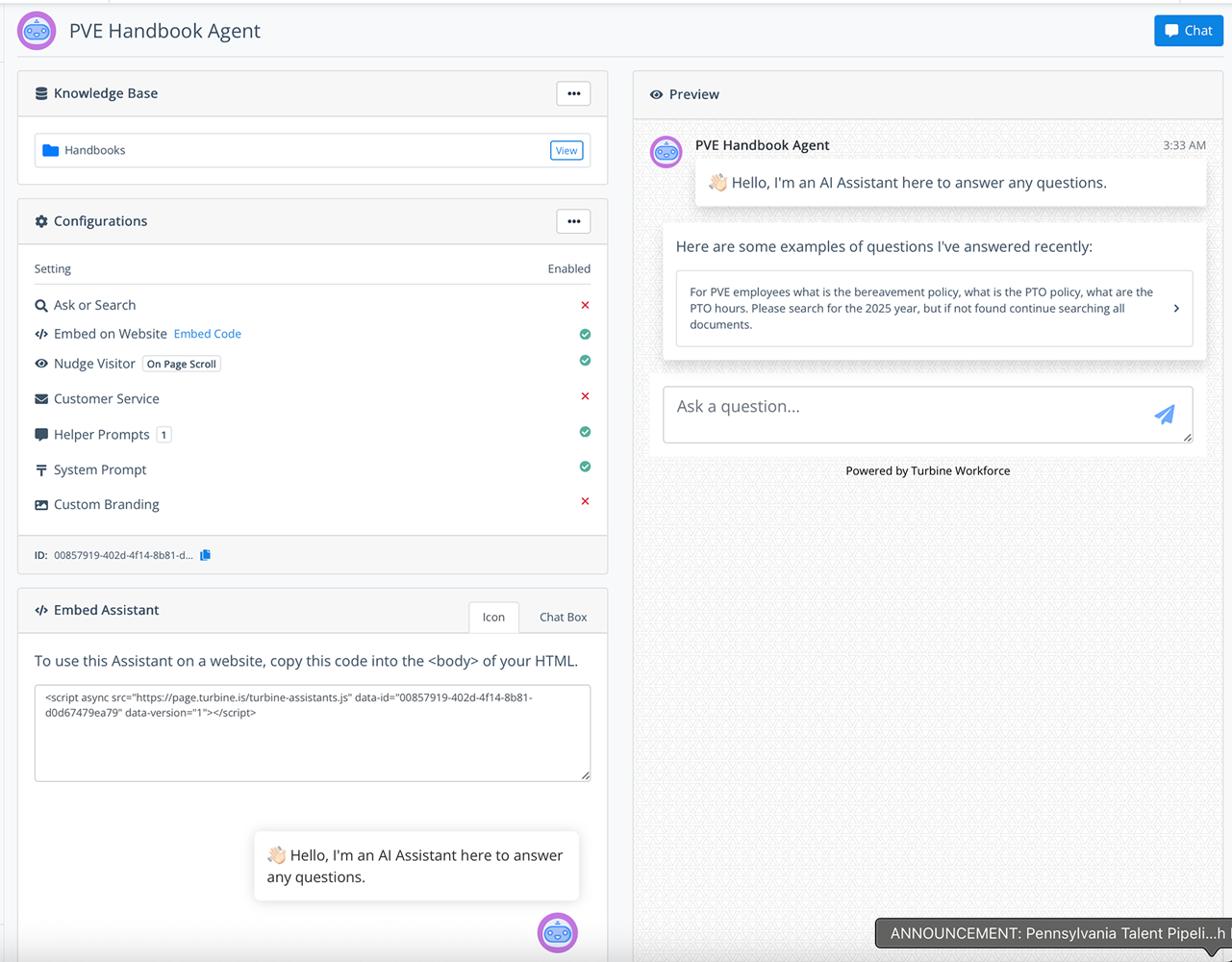
Validate assistant behavior across prompts, retrieval, workflows, and evidence quality before release.
AI is being deployed faster than it can be validated
Organizations are shipping AI that is untested, unverified, and unpredictable, then hoping it works. For many teams, the alternative feels just as bad: expensive hires, custom tooling, and risky deployments before they are ready. It does not scale, and it does not hold up under scrutiny.
What every run captures
- Test inputs, retrieved nodes, and output traces
- Grounding scores, compliance flags, and risk ratings
- Linked prompt, model, dataset, namespace, and org context
- Signed validation records for repeatable review
Introducing AI Test Lab as a Service
A dedicated validation layer for AI systems. Not a prompt playground. A systematic validation engine.
The pipeline now tells the offer more clearly: prepare the data layer, optimize retrieval and embeddings, tune model behavior, validate what comes out, and release with production-ready proof.
Test everything before it hits production
Prompts, models, pipelines, and outputs in one managed validation layer.
Reproducible Test Cases
Define scenarios once, then rerun them across prompts, models, pipelines, and production updates.
Automated Scoring
Combine rule-based checks, schema validation, and AI scoring to evaluate outputs without relying on manual guesswork.
Regression Detection
Compare versions side by side and catch silent degradations before they reach production.
Full Audit Trails
Keep validation logs, scores, and run history for internal review, customer assurance, and compliance needs.
The full AI validation and optimization program
This program covers the path from knowledge quality and retrieval behavior to fine-tuned models, regression testing, audit artifacts, and production-readiness signals.
Data to retrieval to model to output to validation
Most teams stop at prompts and evals. This program extends into model improvement, fine-tuning strategy, and deployment proof.
Custom AI Assistants
Build assistants grounded in your actual data and workflows with domain prompting, controlled knowledge grounding, task-specific behaviors, and versioned prompts.
Outcome: AI that reflects your business, not generic models.
Knowledge Base Quality Assessment
Analyze PDFs, SOPs, databases, and source repositories for structure, consistency, redundancy, conflicts, and retrieval readiness.
Outcome: A clear view of whether your knowledge is usable and where it breaks.
Knowledge Gap Identification
Detect missing topics, weak coverage, ambiguous content, and priority gaps across your target use cases before they fail in production.
Outcome: A targeted roadmap to strengthen your knowledge foundation.
Multi-Embedding Retrieval Testing
Compare up to three embedding approaches across relevance, recall, and ranking quality, including OpenAI, open-source, and domain-tuned options.
Outcome: Optimized retrieval performance for your RAG pipelines.
Fine-Tuned Model Development and Evaluation
Train and validate models tailored to your datasets, tasks, and signals with base-versus-fine-tuned comparisons across accuracy, consistency, and cost efficiency.
Outcome: Higher-quality, more consistent outputs with lower long-term cost.
RAG Pipeline Validation
Evaluate query, retrieval, and response behavior end to end with grounding checks, hallucination detection, and context utilization scoring.
Outcome: Reliable, explainable AI outputs.
Prompt and Model Regression Testing
Run prompt comparisons, model comparisons, before-and-after scoring, and regression alerts so teams can iterate safely.
Outcome: Safe iteration without breaking production systems.
Automated Evaluation and Scoring
Measure every output with rule-based validation, LLM-based reasoning checks, and custom scoring frameworks aligned to your use case.
Outcome: Quantifiable performance instead of subjective opinions.
Test Scenario and Dataset Builder
Create reusable test cases aligned to real workflows using real-world scenarios, edge cases, and blends of synthetic and production data.
Outcome: Repeatable, scalable testing infrastructure.
Validation Reports and Audit Artifacts
Export structured performance summaries, failure analysis, score breakdowns, and validation reports in machine-readable and stakeholder-ready formats.
Outcome: Proof your AI works for internal teams and external stakeholders.
Continuous Monitoring and Drift Detection
Track data, model, and prompt drift over time with alerts when quality or reliability degrades.
Outcome: Long-term reliability, not one-time validation.
Cost and Performance Optimization
Compare cost versus performance, analyze latency, identify inefficient prompts, and determine when fine-tuning is worth the investment.
Outcome: Lower AI spend with higher output quality.
API and CLI Access
Run tests programmatically, integrate validation into CI/CD, and support batch execution when teams need automation.
Outcome: AI validation becomes part of your development lifecycle.
Run prompt, guardrail, and workflow validation inside the same assistant governance surface.
What you gain from validation infrastructure
Know your AI works, not just hope it does
Test prompts, models, pipelines, and outputs in a controlled environment before changes ever reach users.
Validate changes in hours, not weeks
Replace slow manual QA cycles with repeatable evaluations that surface failures quickly and keep release cycles moving.
Understand exactly why outputs pass or fail
Use structured scoring, comparisons, and logs to see what improved, what regressed, and what needs attention.
Generate proof for stakeholders, customers, and regulators
Every run leaves behind evidence that can be reviewed internally or shared externally when reliability must be demonstrated.
A product ladder built to land, expand, and defend margin
Start with validation, expand into optimization, and move into full model and governance infrastructure as requirements mature.
Validate Before You Deploy
Small teams, pilots, early AI adoption
- 1 custom AI assistant
- Knowledge base quality assessment
- Basic knowledge gap analysis
- Retrieval testing with 1 embedding model
- Limited RAG validation scenarios
- Prompt testing and starter dataset builder
- Summary validation report
Outcome: We know if our AI works.
Optimize and Scale AI Performance
Growing teams with production AI use
- Everything in Starter
- Up to 3 custom AI assistants
- Multi-embedding testing up to 3 models
- Advanced RAG validation and regression testing
- Continuous monitoring and drift detection
- Cost and performance optimization insights
- Fine-tuned model evaluation and ROI analysis
Outcome: Our AI is improving and under control.
AI You Can Prove and Defend
Enterprises, regulated industries, AI-first orgs
- Everything in Pro
- Full fine-tuned model development
- Custom evaluation frameworks and compliance-aware rules
- Signed audit artifacts and lineage tracking
- High-scale testing pipelines and CI/CD integration
- Dedicated customization and priority support
Outcome: Our AI is production-grade, defensible, and optimized.
Validation plus optimization
Most competitors stop at prompts and evaluations. This program covers data, retrieval, models, outputs, validation, and model improvement itself so teams can adopt AI with lower cost, lower risk, and a clearer path to production.
No expensive AI team required
Avoid staffing a large internal validation function just to get AI quality under control.
No internal tooling build-out
Skip the time and cost of building bespoke validation infrastructure before you can even start testing.
No manual QA treadmill
Move away from ad hoc reviews and into a production-grade validation system delivered as a service.
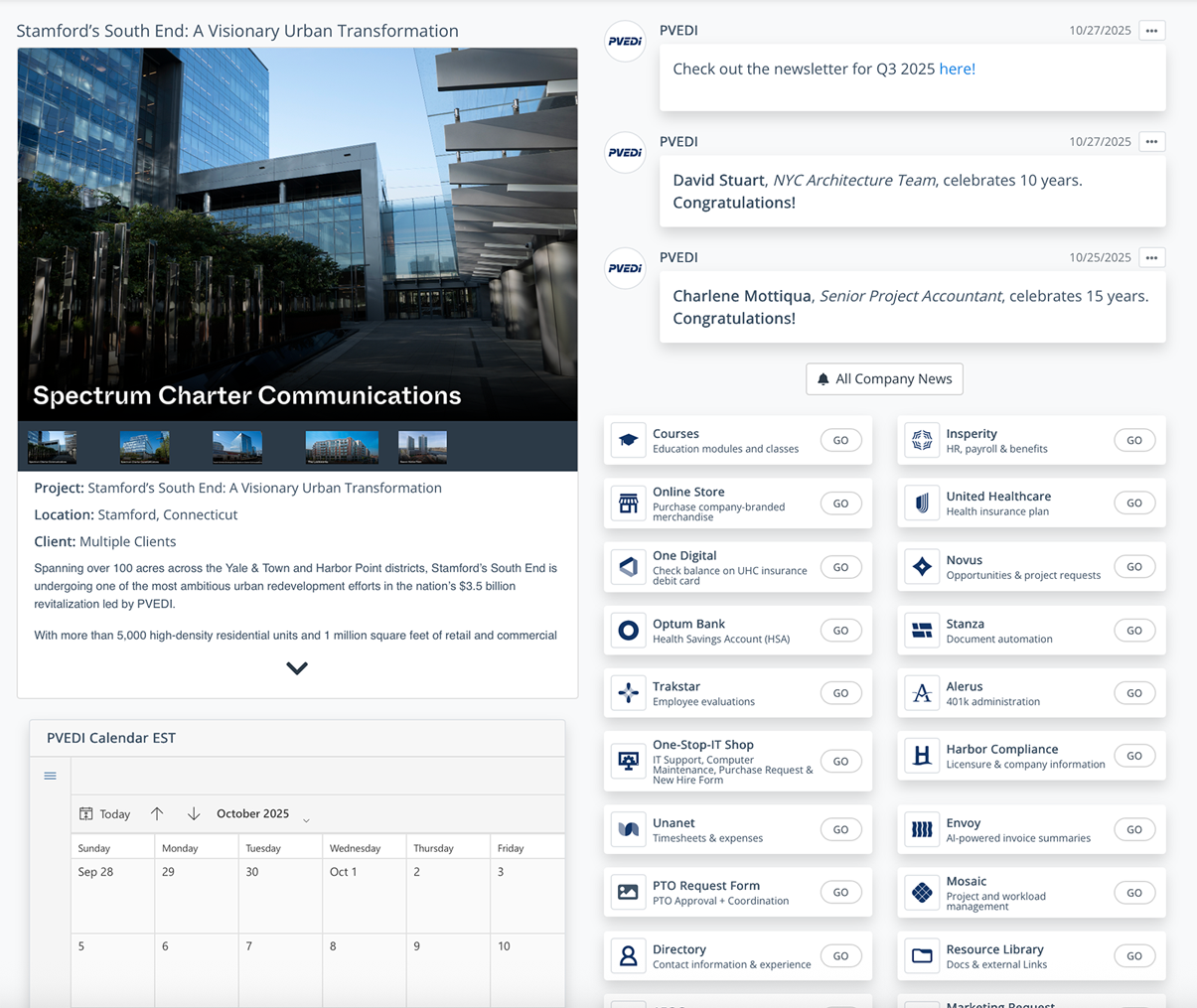
Track risk, drift, quality, and production readiness over time.
Every run sharpens the whole system
Every test run improves your system with better datasets, better prompts, and better models.
Prompts
Models
Pipelines
Outputs
Hugging Face, Laminar, and GitHub
Deliverables can be packaged across model hosting, eval and observability, and version-controlled implementation workflows.
Hugging Face
Models, datasets, embeddings experiments, and deployment-ready artifacts.
Laminar
Tracing, evals, and observability for validation runs, regressions, and release confidence.
GitHub
Versioned prompts, pipelines, evaluation configs, and implementation handoff.
AI without validation is risk
AI with validation is infrastructure.
Start Testing Your AI Today